
DiscoverNet: Unsupervised Video Object Discovery through Discrete Visual Tokenization and Language Model-Inspired Reconstruction
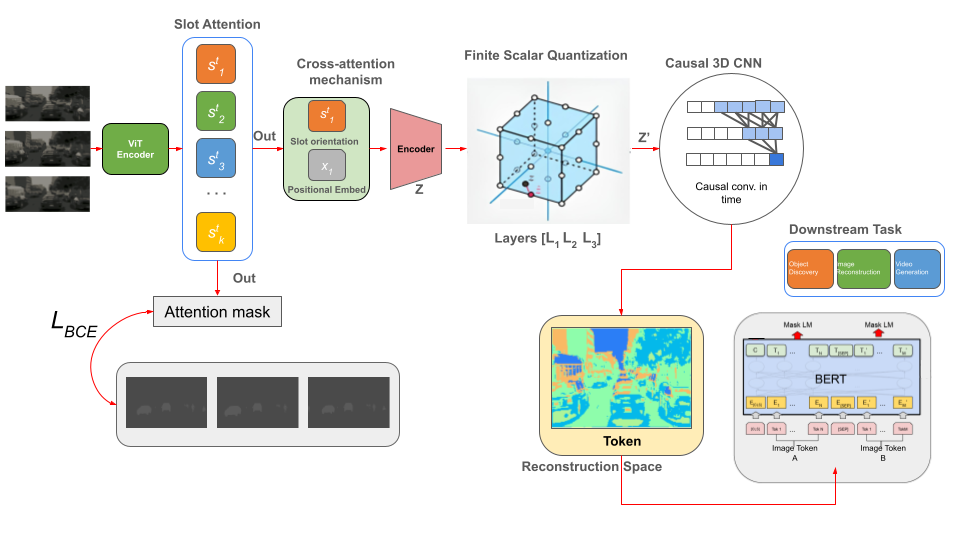
we introduce DiscoverNet, a comprehensive framework that enhances the auto-encoder representation learning approach by incorporating a scalar quantized discrete latent space and reconstruction via a masked language model (LM). Our innovative visual tokenizer enables end-to-end object discovery by harnessing the synergy between discretization and image generation using a bidirectional transformer. The proposed method fosters the development of compatible object-centric features for language models, providing interpretability and memory efficiency.